Dictionaryを高速化する
Dictionaryを高速化する
Dictionaryの作成が遅くなる理由が判明したわけだが、
これはちょっと工夫すれば格段に高速化できる余地がありそうだ。
しかしズバリ言って、現バージョンの吉里吉里ではおそらく解決方法はない。
Dictionaryクラスには内部のハッシュテーブルを操作するような関数が存在しないからだ。
そこで吉里吉里のソースコードをいじる形で、いくつか解決案を考えてみよう。
案1: 検索しないようにする
辞書への要素の追加が重くなっているそもそもの原因は、
同一キーの要素がないか検索を行っている処理にある。
辞書に追加するキーに重複がないと予めわかっている場合は、
この検索処理は完全に無駄な処理だ。
検索処理を省いてしまえば、ハッシュテーブルが小さくても
要素の追加処理の負荷は軽微なものになる。
これは抜本的な解決策のように思える。
例えば要素追加時に検索を行わないようにするDirtyフラグを作り、
絶対に同一キーの要素が追加されないとわかっている時にフラグをONにして要素を追加し、
追加し終わったらフラグをOFFにする…といったような実装が考えられる。
しかし同一キーの要素がないか検索しないということは底知れない危険性を孕んでいる。
人間はミスをする生き物なので、うっかり同一キーの要素を入れてしまったり
何かの手違いでフラグをONにしっぱなしにしてしまう可能性がある。
要素を一気に流し込むassignのような関数内でON/OFFを行うようにすれば
OFFにし忘れるミスは防げるが…人為的ミスが入り込む可能性は依然拭いきれない。
仮に同一キーの要素を複数ハッシュテーブルに追加してしまった場合…
おそらくソレによって生じるバグの原因を突き止めることは相当困難だろう。
検索自体を省く方法は確実に効果が見込めるが、そこには大きなリスクがつきまとう。
案2: 検索を高速化する
検索を省かず、検索処理を見直して高速化する方法はどうだろう。
例えば同一値のリストをただのリストではなく『ソート済みリスト』にする。
ソート済みリストにすればリストの最後まで要素を調べなくても
リストの途中で同一キーの要素がないことを判断することが可能になる。
平均2倍程度の高速化が期待できる。
しかしリストをソート済みリストにすると、
高速化の目的で行われている別のトリックが使えなくなる問題がある。
そのトリックとは、要素が検索された時にその要素をリストの先頭に繰り上げて
次回の検索を最適化する処理だ。
この処理ができなくることとのトレードオフはなんとも難しい。
またこのような挙動変更は互換の点においてもややリスクがある。
案3: ハッシュテーブルを予め大きくしておく
検索が遅くなる原因は、ハッシュテーブルが小さすぎて
同一ハッシュ値の要素のリストがものすごく伸びてしまうことにある。
これは裏を返せば、ハッシュテーブルを予め十分な大きさにしてから
要素を追加すれば問題を回避できるということである。
この方法が効果的なシチュエーションは限定的ではあるが、
検索処理は省かないし、人為的ミスが入り込む余地も少ないし、
挙動も変化しないので、リスクはほとんどないと言っていい。
そして何よりDictionaryの仕組み自体には手を入れないので
ほんの少しの修正で実現可能だ。
ただし追加する要素数が少ない場合は、
ハッシュテーブルの再構築が逆に無駄な処理になるので
ある程度の数で処理を足きりする必要があるだろう。
そのためにも具体的にハッシュテーブルの初期サイズがどのくらいなのか確認しておこう。
吉里吉里のハッシュテーブルの実装はこちら。
tjsObject.h
tjsObject.cpp
初期サイズはtjsObject.hのTJS_NAMESPACE_DEFAULT_HASH_BITSで定義されている。
値は3だ。実際のテーブルサイズは(1<<bits)で計算されるので…
要するに8である。すごく小さい!
そしてこのテーブルサイズにおける適切な要素数は
tjsObject.cppの”decide new hash table size”の部分で行われている計算式に基づけば、
テーブルサイズの半分からその半分の間…つまり2~3である。
ハッシュテーブルのサイズを予め大きくしておくことはかなり効果がありそうだ。
それではこの方向性で具体的な高速化策を考えてみよう。
高速化策1: ハッシュテーブルを再構築する関数を追加する
RebuildHashの仕組みを流用して、ハッシュテーブルを
指定の要素数に適したサイズに再構築するrebuild関数を追加する。
スクリプトで要素を大量に追加する前にこの関数を呼び出すことで
大幅な高速化が期待できる。
高速化策2: ロード時に予め再構築する
辞書に大量の要素を追加する際に極めて重くなるのは、
辞書の読み込み処理においても同じである。
そこで辞書の読み込み処理の部分でも、
ハッシュテーブルを適切なサイズにしてから要素を追加するように改造する。
具体的には辞書に追加する要素をいったんリストに蓄え、
要素数が判明したら再構築を行って、その後で辞書に要素を流し込むようにする。
高速化策3: アサイン時に予め再構築する
配列や辞書のアサイン時にもはやり同様に重くなる。
アサイン時には追加要素数は自明なので、この改造はすごく簡単だ。
実験してみる
で、実際にこの3つの対策を施したexeを作りテストしてみた。
テストスクリプトは以下の通りだ。
class SimpleWindow extends Window
{
function SimpleWindow()
{
super.Window();
add(new Layer(this, null));
visible = true;
}
function finalize()
{
super.finalize();
}
}
var win = new SimpleWindow();
Debug.console.visible = true;
//////////////////////////////////////////////////////////////////////
// 補助
//////////////////////////////////////////////////////////////////////
// 計測開始/終了
var g_timeBegin;
function testBegin()
{
System.doCompact(); // メモリ強制開放
g_timeBegin = System.getTickCount();
}
function testEnd()
{
return System.getTickCount() - g_timeBegin;
}
//////////////////////////////////////////////////////////////////////
// テスト本体
//////////////////////////////////////////////////////////////////////
var FIND_NUM = 1000; // 検索回数
var FILE_NAME = System.dataPath+"test.txt"; // 一時ファイル名
function testMain(CreateNum, testCase, count)
{
//------------------------------------------------------------------
// 準備
//------------------------------------------------------------------
var CREATE_NUM = CreateNum; // 作成要素数
// 検索対象をランダムに作成
// *2 して「ヒットしないもの」も探す
var findTable = [];
for (var i = 0; i < FIND_NUM; i++)
{
findTable[i] = int (Math.random()*(CREATE_NUM*2-1));
}
//------------------------------------------------------------------
// 配列
//------------------------------------------------------------------
// 作成
var array1 = [];
testBegin();
for(var i = 0; i < CREATE_NUM; i++)
{
var name = "hash_number_is_" + "%06d".sprintf(i);
array1[i] = name;
}
var timeArrayCreate = testEnd();
// 保存
testBegin();
array1.saveStruct(FILE_NAME);
var timeArraySave = testEnd();
// 読み込み
testBegin();
var array2 = Scripts.evalStorage(FILE_NAME);
var timeArrayLoad = testEnd();
// アサイン実行
testBegin();
var array3 = [];
array3.assign(array1);
var timeArrayAssignA = testEnd();
// 検索
// findは返り値を受けとらないと処理されないことに注意
testBegin();
var temp;
for (var i = 0; i < FIND_NUM; i++)
temp = array1.find("hash_number_is_" + "%06d".sprintf(findTable[i]));
var timeArrayFind = testEnd();
//------------------------------------------------------------------
// 辞書
//------------------------------------------------------------------
// 作成
var dictionary1 = %[];
testBegin();
for(var i = 0; i < CREATE_NUM; i++)
{
var name = "hash_number_is_" + "%06d".sprintf(i);
dictionary1[name] = i;
}
var timeDictionaryCreate = testEnd();
// 作成2(指定数でRebuildHashする)
var dictionaryX = %[];
var timeDictionaryCreate2 = -1;
if(typeof global.Dictionary.rebuild != "undefined")
{
testBegin();
(global.Dictionary.rebuild incontextof dictionaryX)(CREATE_NUM); // 追加関数
for(var i = 0; i < CREATE_NUM; i++)
{
var name = "hash_number_is_" + "%06d".sprintf(i);
dictionaryX[name] = i;
}
timeDictionaryCreate2 = testEnd();
}
// 保存
testBegin();
(global.Dictionary.saveStruct incontextof dictionary1)(FILE_NAME);
var timeDictionarySave = testEnd();
// 読み込み
testBegin();
var dictionary2 = Scripts.evalStorage(FILE_NAME);
var timeDictionaryLoad = testEnd();
// アサイン実行(辞書:assign)
testBegin();
var dictionary3 = %[];
(global.Dictionary.assign incontextof dictionary3)(dictionary1);
var timeDictionaryAssignD = testEnd();
// アサイン用配列作成
var dictionary_array = [];
for(var i = 0; i < CREATE_NUM; i++)
{
var name = "hash_number_is_" + "%06d".sprintf(i);
dictionary_array[i*2] = name;
dictionary_array[i*2+1] = i;
}
// アサイン実行(配列)
testBegin();
var dictionary4 = %[];
(global.Dictionary.assign incontextof dictionary4)(dictionary_array);
var timeDictionaryAssignA = testEnd();
// アサイン実行(辞書:assignStruct)
testBegin();
var dictionary5 = %[];
(global.Dictionary.assignStruct incontextof dictionary5)(dictionary1);
var timeDictionaryAssignS = testEnd();
// 辞書検索時間測定
testBegin();
for (var i = 0; i < FIND_NUM; i++)
temp = dictionary1["hash_number_is_" + "%06d".sprintf(findTable[i])];
var timeDictionaryFind = testEnd();
// 辞書検索時間測定(指定数でRebuildHashしたもの)
var timeDictionaryFind2 = -1;
if(timeDictionaryCreate2 != -1)
{
testBegin();
for (var i = 0; i < FIND_NUM; i++)
temp = dictionaryX["hash_number_is_" + "%06d".sprintf(findTable[i])];
timeDictionaryFind2 = testEnd();
}
//------------------------------------------------------------------
// 記録
//------------------------------------------------------------------
data_timeArrayCreate[testCase][count] = timeArrayCreate;
data_timeArraySave[testCase][count] = timeArraySave;
data_timeArrayLoad[testCase][count] = timeArrayLoad;
data_timeArrayAssignA[testCase][count] = timeArrayAssignA;
data_timeArrayFind[testCase][count] = timeArrayFind;
data_timeDictionaryCreate[testCase][count] = timeDictionaryCreate;
data_timeDictionaryCreate2[testCase][count] = timeDictionaryCreate2;
data_timeDictionarySave[testCase][count] = timeDictionarySave;
data_timeDictionaryLoad[testCase][count] = timeDictionaryLoad;
data_timeDictionaryAssignD[testCase][count] = timeDictionaryAssignD;
data_timeDictionaryAssignA[testCase][count] = timeDictionaryAssignA;
data_timeDictionaryAssignS[testCase][count] = timeDictionaryAssignS;;
data_timeDictionaryFind[testCase][count] = timeDictionaryFind;
data_timeDictionaryFind2[testCase][count] = timeDictionaryFind2;
//------------------------------------------------------------------
// 後始末
//------------------------------------------------------------------
invalidate findTable;
invalidate array1;
invalidate array2;
invalidate array3;
invalidate dictionary1;
invalidate dictionary2;
invalidate dictionary3;
invalidate dictionary4;
invalidate dictionary5;
invalidate dictionary_array;
invalidate dictionaryX;
}
//////////////////////////////////////////////////////////////////////
// テストループ
//////////////////////////////////////////////////////////////////////
var data_createNum = [];
var data_timeArrayCreate = [];
var data_timeArraySave = [];
var data_timeArrayLoad = [];
var data_timeArrayAssignA = [];
var data_timeArrayFind = [];
var data_timeDictionaryCreate = [];
var data_timeDictionaryCreate2 = [];
var data_timeDictionarySave = [];
var data_timeDictionaryLoad = [];
var data_timeDictionaryAssignD = [];
var data_timeDictionaryAssignA = [];
var data_timeDictionaryAssignS = [];
var data_timeDictionaryFind = [];
var data_timeDictionaryFind2 = [];
var testCase = 0;
for(var CreateNum=100000; CreateNum<=100000; CreateNum+=10000)
{
data_createNum[testCase] = CreateNum;
// 計測データを格納する配列を作成
data_timeArrayCreate[testCase] = new Array();
data_timeArraySave[testCase] = new Array();
data_timeArrayLoad[testCase] = new Array();
data_timeArrayAssignA[testCase] = new Array();
data_timeArrayFind[testCase] = new Array();
data_timeDictionaryCreate[testCase] = new Array();
data_timeDictionaryCreate2[testCase] = new Array();
data_timeDictionarySave[testCase] = new Array();
data_timeDictionaryLoad[testCase] = new Array();
data_timeDictionaryAssignD[testCase] = new Array();
data_timeDictionaryAssignA[testCase] = new Array();
data_timeDictionaryAssignS[testCase] = new Array();
data_timeDictionaryFind[testCase] = new Array();
data_timeDictionaryFind2[testCase] = new Array();
// 割り込みによって値にぶれが出る場合があるので
// 同じケースについて何度か計測する
// 計測したうちのもっとも小さい値を使う
for(var count=0; count<5; count++)
{
testMain(CreateNum, testCase, count);
}
// 計測データを昇順にソート
data_timeArrayCreate[testCase].sort();
data_timeArraySave[testCase].sort();
data_timeArrayLoad[testCase].sort();
data_timeArrayAssignA[testCase].sort();
data_timeArrayFind[testCase].sort();
data_timeDictionaryCreate[testCase].sort();
data_timeDictionaryCreate2[testCase].sort();
data_timeDictionarySave[testCase].sort();
data_timeDictionaryLoad[testCase].sort();
data_timeDictionaryAssignD[testCase].sort();
data_timeDictionaryAssignA[testCase].sort();
data_timeDictionaryAssignS[testCase].sort();
data_timeDictionaryFind[testCase].sort();
data_timeDictionaryFind2[testCase].sort();
// 出力
Debug.message("===========================================");
Debug.message("create num : %8d"
.sprintf(data_createNum[testCase]));
Debug.message("find num : %8d"
.sprintf(FIND_NUM));
Debug.message("array create : %8d ms"
.sprintf(data_timeArrayCreate[testCase][0]));
Debug.message("array save : %8d ms"
.sprintf(data_timeArraySave[testCase][0]));
Debug.message("array load : %8d ms"
.sprintf(data_timeArrayLoad[testCase][0]));
Debug.message("array assignA : %8d ms ※arrayをassign"
.sprintf(data_timeArrayAssignA[testCase][0]));
Debug.message("array find : %8d ms"
.sprintf(data_timeArrayFind[testCase][0]));
Debug.message("dictionary create : %8d ms"
.sprintf(data_timeDictionaryCreate[testCase][0]));
Debug.message("dictionary create2 : %8d ms ※予めrebuildしたもの"
.sprintf(data_timeDictionaryCreate2[testCase][0]));
Debug.message("dictionary save : %8d ms"
.sprintf(data_timeDictionarySave[testCase][0]));
Debug.message("dictionary load : %8d ms"
.sprintf(data_timeDictionaryLoad[testCase][0]));
Debug.message("dictionary assignD : %8d ms ※dictionaryをassign"
.sprintf(data_timeDictionaryAssignD[testCase][0]));
Debug.message("dictionary assignA : %8d ms ※arrayをassign"
.sprintf(data_timeDictionaryAssignA[testCase][0]));
Debug.message("dictionary assignS : %8d ms ※dictionaryをassignStruct"
.sprintf(data_timeDictionaryAssignS[testCase][0]));
Debug.message("dictionary find : %8d ms"
.sprintf(data_timeDictionaryFind[testCase][0]));
Debug.message("dictionary find2 : %8d ms ※予めrebuildしたもの"
.sprintf(data_timeDictionaryFind2[testCase][0]));
Debug.message("===========================================");
testCase++;
}
ループしてないfor文や、いちいちデータを蓄えてる無駄っぽい処理はグラフ作成用である。
まずは改造前のkrkr.exeで速度を計測してみよう。
手持ちの2.32.2.426で試した。
create num : 100000
find num : 1000
array create : 77 ms
array save : 515 ms
array load : 127 ms
array assignA : 1 ms ※arrayをassign
array find : 5311 ms
dictionary create : 5685 ms
dictionary create2 : -1 ms ※予めrebuildしたもの
dictionary save : 976 ms
dictionary load : 2579 ms
dictionary assignD : 1355 ms ※dictionaryをassign
dictionary assignA : 5252 ms ※arrayをassign
dictionary assignS : 1327 ms ※dictionaryをassignStruct
dictionary find : 85 ms
dictionary find2 : -1 ms ※予めrebuildしたもの
そしてこちらが改造版。
create num : 100000
find num : 1000
array create : 90 ms
array save : 549 ms
array load : 121 ms
array assignA : 2 ms ※arrayをassign
array find : 5402 ms
dictionary create : 5646 ms
dictionary create2 : 88 ms ※予めrebuildしたもの
dictionary save : 1025 ms
dictionary load : 216 ms
dictionary assignD : 32 ms ※dictionaryをassign
dictionary assignA : 18 ms ※arrayをassign
dictionary assignS : 32 ms ※dictionaryをassignStruct
dictionary find : 86 ms
dictionary find2 : 1 ms ※予めrebuildしたもの
軽く10~100倍速くなってる!
ちょっと驚きの数字だが、もっともこれはあくまで追加する要素数が10万個の場合の数値である。
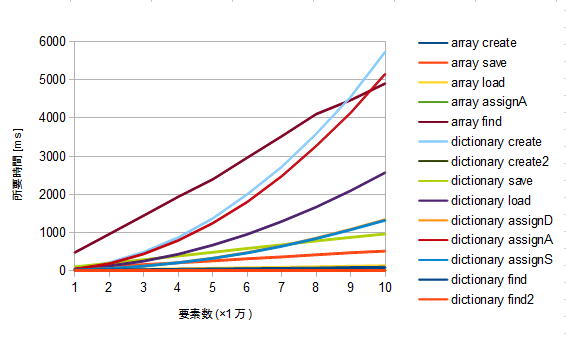
辞書の作成が重い原因は、リストが伸びれば伸びるほど検索に時間がかかることに起因しているので
要素数に対する処理時間のグラフは2次曲線を描く。
またキーとなっている文字列の長さも大きく影響している。
つまり追加する要素数がめちゃくちゃ多いからこそこれほど劇的な差になっているのであって
これをもってして辞書が超高速になったと思うのは早合点である。
しかしこの高速化策によって要素数に対する処理時間のグラフは一次曲線(直線)になる。
この高速化策は導入コストもリスクも低いので、ほとんどの場合有用だろう。
実際にグラフを作ってみたのでご覧いただきたい。
改造前
改造版
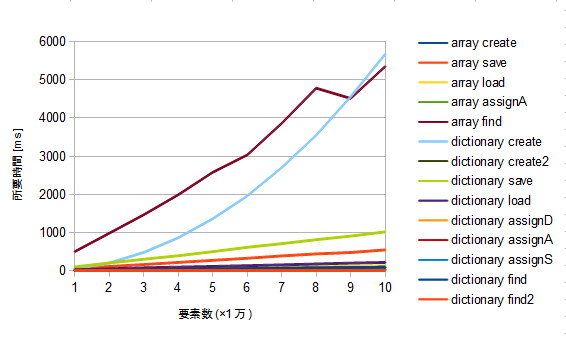
検索のグラフがちょっとがくがくしてるが、検索回数が少ないのと、
検索をランダムにしているためだろう。検索回数は1000回固定である。
まとめると…
Dictionaryは決して遅くはない。むしろ速い。
しかし使い方を誤ると極端に遅くなってしまう場合がある。
けれどもその仕組みを理解し適切に扱うことで問題を回避できる。
ということである。
ご参考までに。